Your Deep-Learning Journey
This post is a summary of the first chapter of the book Deep Learning for Coders with fastai and PyTorch. This book is written by Jeremy Howard and Sylvain Gugger. I hope this summary will help you to understand the basics of deep learning and fastai library.
Neural Networks: A Brief History
- In 1943 Warren McCulloch, a neurophysiologist, and Walter Pitts, a logician, teamed up to develop a mathematical model of an artificial neuron.
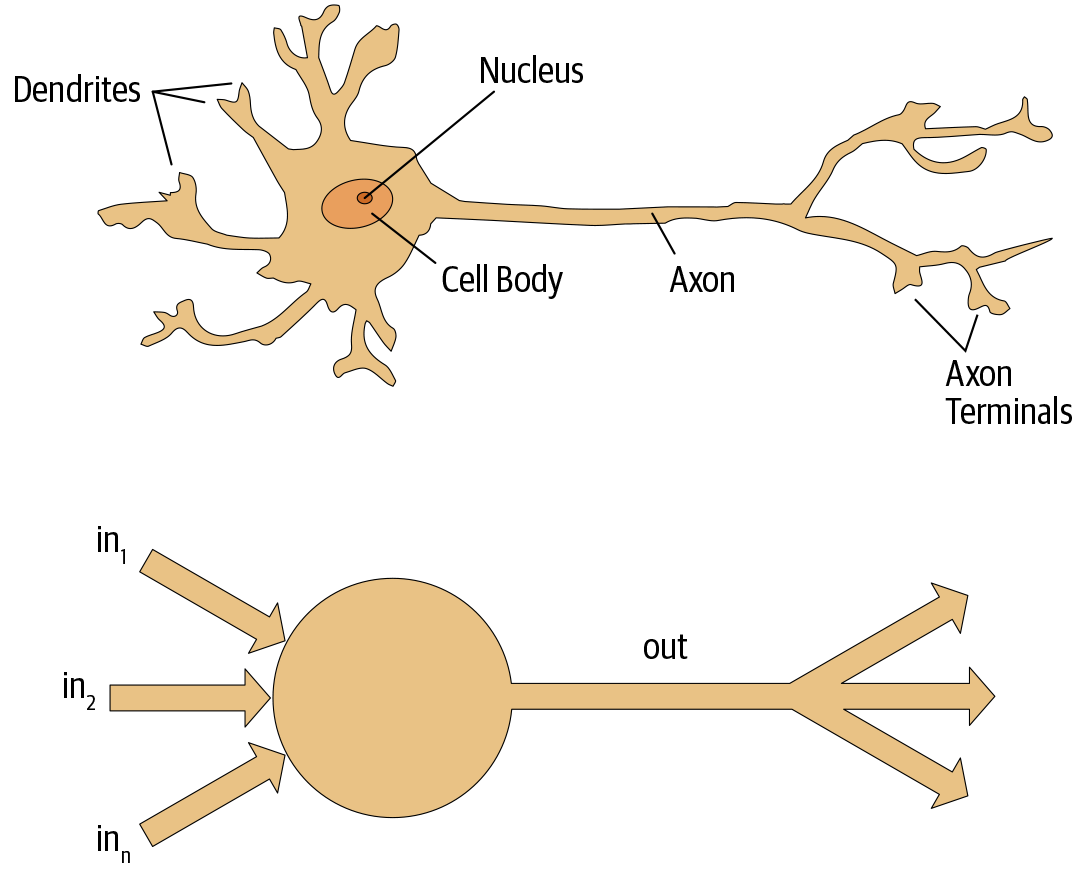
- Rosenblatt further developed the artificial neuron to give it the ability to learn. He worked on building the first device that used these principles, the Mark I Perceptron.
The Mark I Perceptron, developed by Frank Rosenblatt in 1958 at the Cornell Aeronautical Laboratory, is one of the first artificial neural networks designed for pattern recognition tasks. The concept of the Perceptron forms the basis for today's deep learning neural networks.
- In The Design of an Intelligent Automaton, Rosenblatt wrote about this work: “We are now about to witness the birth of such a machine—a machine capable of perceiving, recognizing and identifying its surroundings without any human training or control.”
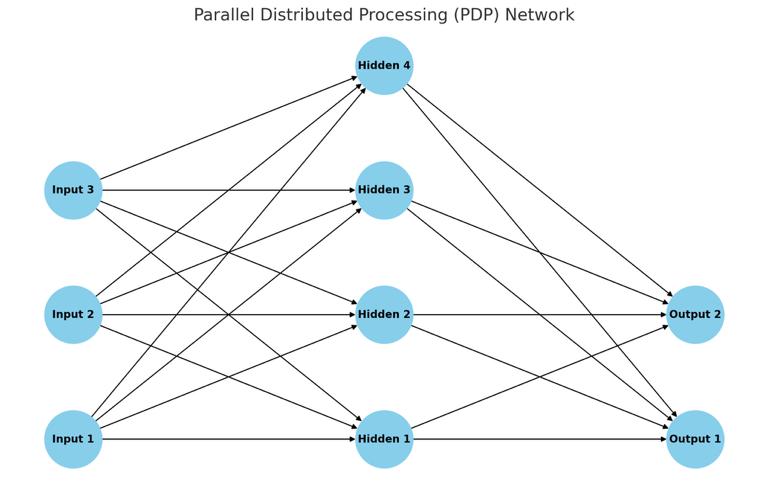
- The most pivotal work in neural networks in the last 50 years was the multivolume Parallel Distributed Processing (PDP) by David Rumelhart, James McClelland, and the PDP Research Group, released in 1986 by MIT Press.
Parallel Distributed Processing (PDP) is a framework for understanding neural networks and cognitive processes. Parallel Distributed Processing (PDP) is a cognitive framework that models mental processes through networks of interconnected units working simultaneously. Information is represented across these units, with learning and adaptation achieved by adjusting the strengths of their connections. This approach mirrors how the brain processes information, emphasizing distributed representation and parallel processing to explain cognitive functions like perception and memory.
Deep-Learning
- Deep learning models use neural networks, which originally date from the 1950s and have become powerful very recently thanks to recent advancements.
- In deep learning, it really helps if you have the motivation to fix your model to get it to do better.
- Deep learning can be set to work on almost any problem.
- Common character traits in the people who do well at deep learning include playfulness and curiosity.
- A dataset is a bunch of data, it could be images, emails, financial indicators, sounds, or anything else.
First Model (Predict Cats)
%%capture
!pip install fastai fastbook ipywidgets
from fastai.vision.all import *
from ipywidgets import widgets, Button
from IPython.display import display, clear_output
path = untar_data(URLs.PETS) / 'images'
def is_cat(x): return x[0].isupper()
dls = ImageDataLoaders.from_name_func(
path,
get_image_files(path),
valid_pct=0.2,
seed=42,
label_func=is_cat,
item_tfms=Resize(224)
)
learn = vision_learner(dls, resnet34, metrics=error_rate)
learn.fine_tune(1)
# Create widgets
uploader = widgets.FileUpload(accept='image/*', multiple=False)
predict_button = widgets.Button(description='Predict')
output = widgets.Output()
def on_predict_click(b):
with output:
clear_output()
if not uploader.value:
print("Please upload an image first.")
return
img_file = list(uploader.value.values())[0]
img = PILImage.create(img_file['content'])
is_cat, _, probs = learn.predict(img)
print(f"Is this a cat?: {is_cat}.")
print(f"Probability it's a cat: {probs[1].item():.6f}")
predict_button.on_click(on_predict_click)
# Display widgets
display(uploader, predict_button, output)
-
path: The root directory containing your image files. -
get_image_files(path): A function to retrieve image file paths within the specified directory. -
valid_pct=0.2: The percentage of data to be used for validation (20% in this case). -
seed=42: A random seed for reproducible data splits. -
label_func=is_cat: A function to determine the label for each image (True for cat, False otherwise). -
item_tfms=Resize(224): A transformation to resize each image to 224x224 pixels.
The
error rateis the proportion of images that were incorrectly identified. It serves as our metric—our measure of model quality, chosen to be intuitive and comprehensible
Machine Learning
- Machine learning is, like regular programming, a way to get computers to complete a specific task.

- Right back at the dawn of computing, in 1949, an IBM researcher named Arthur Samuel started working on a different way to get computers to complete tasks, which he called machine learning.
- Arthur basic idea was this: instead of telling the computer the exact steps required to solve a problem, show it examples of the problem to solve, and let it figure out how to solve it itself.
A machine can learn by testing how well it's doing and automatically adjusting its internal settings to get better.
- In machine learning, the weight assignments (or simply "weights") are numerical values that determine how the program processes its input and generates its output.
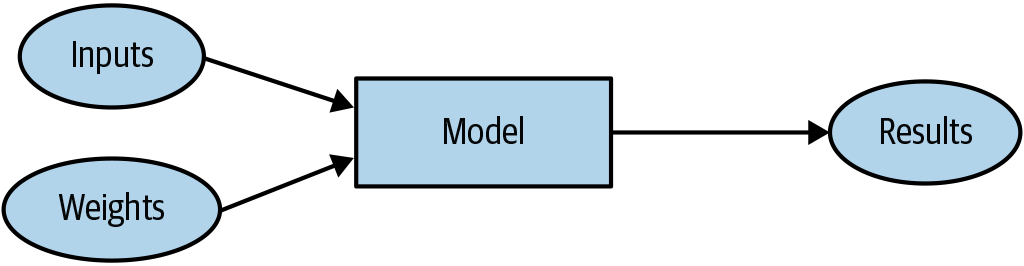
- The model is a special kind of program: it’s one that can do many different things, depending on the weights.
“weights” and “model parameters” are used interchangeably. They both refer to the numerical values within a model that are learned during training and directly determine the model's behavior. Weights are values that adjust during the training process to minimize the error in the network's predictions. They are used to strengthen or weaken the signals between the neurons in the network layers, effectively learning the patterns in the input data to make accurate predictions or classifications. Adjusting these weights allows the ANN to optimize its performance by iteratively improving its output accuracy based on the given training data. In most deep learning frameworks, when you “save a model,” you’re primarily saving the model’s learned parameters (or weights). These numerical values are what the training process adjusts, and they ultimately define how the model makes predictions. When you load the model, the framework restores those weights (or parameters) to reconstruct the model state exactly as it was at save time, allowing you to perform inference or continue training from that point.
- What Samuel called “weights” are most generally referred to as model parameters these days.
- Next, Samuel said we need an automatic means of testing the effectiveness of any current weight assignment in terms of actual performance. (Loss function).
The loss function is a mathematical function that measures how well the model's predictions match the actual target values. It quantifies the difference (or "loss") between the predicted outputs and the ground truth labels during training. The goal of training is to minimize this loss, thereby improving the model's effectiveness in making accurate predictions. The loss function is typically evaluated on every batch during training, and its result is used to guide the optimization process in every epoch (SGD).
- Finally, we need a mechanism for altering the weight assignment so as to maximize the performance. For instance, we could look at the difference in weights between the winning model and the losing model, and adjust the weights a little further in the winning direction. (Gradient Descent)
The loss function works hand-in-hand with SGD (or its variants). The loss function measures how far the model's predictions are from the target, and SGD uses this information to adjust the model's parameters to reduce the loss and improve performance.
- Learning would become entirely automatic when the adjustment of the weights was also automatic.

- Also note that once the model is trained—that is, once we’ve chosen our final, best, favorite weight assignment—then we can think of the weights as being part of the model, since we’re not varying them anymore.
- A trained model can be treated just like a regular computer program.

Artificial Neural Network (ANN)
- ANN is a function that is so flexible that it could be used to solve any given problem, just by varying its weights.
- If you regard a neural network as a mathematical function, it turns out to be a function that is extremely flexible depending on its weights.
- The fact that neural networks are so flexible means that, in practice, they are often a suitable kind of model, and you can focus your effort on the process of training them—that is, of finding good weight assignments.
- You might need to find a new mechanism for automatically updating weights in machine learning models. One such mechanism is called stochastic gradient descent (SGD).
The core idea of SGD is to update the model's parameters (weights and biases) incrementally after evaluating each training example or a small batch of training examples. This differs from traditional gradient descent, which uses the entire dataset to calculate the gradient before updating the parameters. In the case of image classification, a batch refers to a small group of images (e.g., 32, 64, or 128 images) processed together at once. The model computes predictions, evaluates the loss, and updates parameters for each batch during training. This process is repeated for all batches in the dataset within an epoch. An
epochis one full pass through the entire dataset, while abatchis a smaller subset of the data processed at once during training.
- A neural network is a particular kind of machine learning model, which fits right in to Samuel’s original conception.
- Neural networks are special because they are highly flexible, which means they can solve an unusually wide range of problems just by finding the right weights.
Arthur Samuel used a technique called rote learning and a form of reinforcement learning in his checkers-playing program. Rote Learning: The program memorized board positions and associated scores (based on expert play) during training. This knowledge base was used to evaluate possible moves and choose the best one during gameplay. Reinforcement Learning: The program also learned by playing against itself and adjusting its scoring function based on the outcomes of games. Winning moves would reinforce the patterns that led to them, while losing moves would be penalized. This gradual improvement through trial and error is a core concept of reinforcement learning.
- We can simply define our model’s performance as its accuracy at predicting the correct answers.
A Bit of Deep Learning Jargon
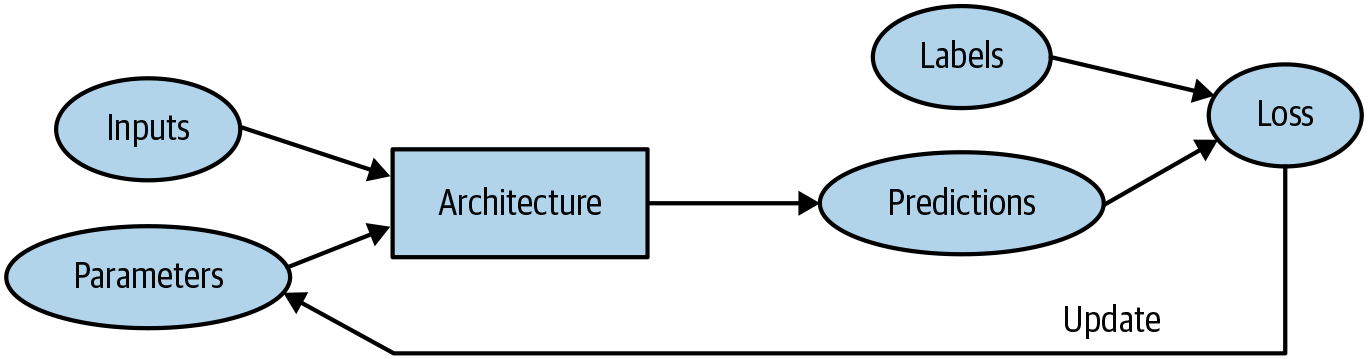
- Here is the modern deep learning terminology for all the pieces we have discussed:
- The functional form of the model is called its architecture (but be careful, sometimes people use model as a synonym of architecture, so this can get confusing).
- The weights are called parameters.
- The predictions are calculated from the independent variable, which is the data not including the labels.
- The results of the model are called predictions.
- The measure of performance is called the loss.
- The loss depends not only on the predictions, but also on the correct labels (also known as targets or the dependent variable); e.g., “dog” or “cat.”
In machine learning, the phrase "functional form of the model" refers to the mathematical structure that defines how the model makes predictions. This includes the types of operations (like addition, multiplication, etc.) and the arrangement of these operations.
Limitations Inherent to Machine Learning
- It’s not enough to just have examples of input data; we need labels for that data too (e.g., pictures of dogs and cats aren’t enough to train a model; we need a label for each one, saying which ones are dogs and which are cats).
- We’ve seen that most organizations that say they don’t have enough data actually mean they don’t have enough labeled data.
Predictive policing refers to the use of machine learning models to forecast where and when crimes are likely to occur. These models are often trained on historical crime data, such as locations of past arrests.
- The more the model is used (model's inference phase), the more biased the data becomes, making the model even more biased.
If a model is trained on data heavily biased toward a specific political view, it is very likely that the model will reflect and propagate that view in its responses or predictions. This happens because machine learning models learn patterns and associations from their training data, and if the data predominantly represents one perspective, the model will internalize and reinforce that perspective.
How Our Image Recognizer Works
-
label_func: Computer vision datasets are normally structured in such a way that the label for an image is part of the filename or path—most commonly the parent folder name. -
item_tfms: Why 224 pixels? This is the standard size for historical reasons (old pre-trained models require this size exactly), but you can pass pretty much anything. If you increase the size, you’ll often get a model with better results (since it will be able to focus on more details), but at the price of speed and memory consumption; the opposite is true if you decrease the size. -
untar_data: The Pet dataset contains 7,390 pictures of dogs and cats, consisting of 37 breeds. Each image is labeled using its filename: for instance, the filegreat_pyrenees_173.jpgis the 173rd example of an image of a Great Pyrenees breed dog in the dataset. _The filenames start with an uppercase letter if the image is a cat, and a lowercase letter otherwise. -
from_name_func: means that filenames can be extracted using a function applied to the filename. -
validpct: This tells fastai to hold out 20% of the data and not use it for training the model at all. This 20% of the data is called the validation set; the remaining 80% is called the training set. The 20% that is held out is selected randomly.
Validation set is used to measure the accuracy of the model
-
seed: Sets the random seed to the same value every time we run this code, which means we get the same validation set every time we run it.
fastai will always show you your model’s accuracy using only the validation set, never the training set.
- If you train a large enough model for a long enough time, it will eventually memorize the label of every item in your dataset.
- Our goal when creating a model: for it to be useful on data that the model sees only in the future, after it has been trained.
- Even when your model has not fully memorized all your data, earlier on in training it may have memorized certain parts of it.
- The longer you train for, the better your accuracy will get on the training set.
- If you train for too long, with not enough data, you will see the accuracy of your model start to get worse (this is called overfitting). Overfitting is the single most important and challenging issue.
In machine learning, overfitting happens when a model learns the training data too well. Instead of learning the general patterns, it focuses on the specific details and noise in the data. This makes it good at predicting the training data, but bad at predicting new data it hasn't seen before.
Think of overfitting like the model memorizing the answers instead of understanding the underlying concept. This makes it perform poorly on new data it hasn't seen before.
- It is easy to create a model that does a great job at making predictions on the exact data it has been trained on, but it is much harder to make accurate predictions on data the model has never seen before.
- We often see practitioners using overfitting avoidance techniques even when they have enough data that they didn’t need to do so, ending up with a model that may be less accurate than what they could have achieved.
- When you train a model, you must always have both a training set and a validation set.
- You must measure the accuracy of your model only on the validation set.
- fastai defaults
valid_pctto0.2, so even if you forget, fastai will create a validation set for you. - CNN is the state-of-the-art approach to creating computer vision models.
Convolutional neural network (CNN) is a type of AI neural network specifically designed for processing structured data like images or audio.
- Picking an architecture (like ResNet-32, ResNet-50, or others) isn’t a very important part of the deep learning process. It’s something that academics love to talk about, but in practice it is unlikely to be something you need to spend much time on.
- We’re using an architecture called ResNet; it is both fast and accurate for many datasets and problems.
- The 34 in
resnet34refers to the number of layers in this variant of the architecture (other options are 18, 50, 101, and 152). - Models using architectures with more layers take longer to train and are more prone to overfitting.
-
metric: is a function that measures the quality of the model’s predictions using the validation set, and will be printed at the end of each epoch. -
error_rate: is a function provided by fastai that does just what it says: tells you what percentage of images in the validation set are being classified incorrectly. - Another common metric for classification is accuracy (which is just 1.0 -
error_rate)._ - The purpose of loss is to define a “measure of performance” that the training system can use to update weights automatically.
-
vision_learneralso has a parameterpretrained, which defaults toTrue(so it’s used in this case, even though we haven’t specified it), which sets the weights in your model to values that have already been trained by experts to recognize a thousand different categories across 1.3 million photos (using the famous ImageNet dataset). - Using pretrained models is the most important method we have to allow us to train more accurate models, more quickly, with less data and less time and money.
- Transfer learning: is using a pretrained model for a task different from what it was originally trained for.
A Transfer learning technique that updates the parameters of a pretrained model by training for additional epochs using a different task from that used for pretraining.
- To fit a model, we have to provide at least one piece of information: how many times to look at each image (known as number of epochs).
- How
fine_tunemethod works:-
Initial Short Training (Freeze Everything but the Head):
- Run 1 epoch training only the newly added “head” (the part specific to your dataset).
- This step helps the head “catch up” without overwriting the pre-trained knowledge in the earlier layers.
-
Full Model Fine-Tuning (Unfreeze & Train All Layers):
- Next, train for the requested number of epochs, unfreezing the entire model.
- The later layers (including the head) receive larger updates, while the earlier (pre-trained) layers receive smaller updates, preserving the general features they already learned.
-
Initial Short Training (Freeze Everything but the Head):
-
Example:
- Suppose you start with a ResNet pre-trained on ImageNet (which learned to classify 1,000 categories).
- You replace ResNet’s final classification layer (originally predicting 1,000 classes) with a new head that predicts just the classes in your dataset (e.g., cats vs. dogs).
- During the first epoch, only this new head is trained. Then you unfreeze and fine-tune the entire ResNet in subsequent epochs.
The head of a model is the part that is newly added to be specific to the new dataset. An epoch is one complete pass through the dataset.
- All kinds of machine learning models (including deep learning and traditional statistical models) can be challenging to fully understand.
- An image recognizer can, as its name suggests, only recognize images. But a lot of things can be represented as images, which means that an image recognizer can learn to complete many tasks. Example: a sound can be converted to a spectrogram.
A spectrogram is a visual representation of the spectrum of frequencies of a signal as it varies with time. When applied to an audio signal, spectrograms are sometimes called sonographs, voiceprints, or voicegrams. When the data are represented in a 3D plot they may be called waterfall displays.
Jargon Recap
| Term | Meaning |
|---|---|
| Label | The data that we’re trying to predict, such as “dog” or “cat” |
| Architecture | The template of the model that we’re trying to fit; i.e., the actual mathematical function that we’re passing the input data and parameters to |
| Model | The combination of the architecture with a particular set of parameters |
| Parameters | The values in the model that change what task it can do and that are updated through model training |
| Fit | Update the parameters of the model such that the predictions of the model using the input data match the target labels |
| Train | A synonym for fit |
| Pretrained model | A model that has already been trained, generally using a large dataset, and will be fine-tuned |
| Fine-tune | Update a pretrained model for a different task |
| Epoch | One complete pass through the input data |
| Loss | A measure of how good the model is, chosen to drive training via SGD |
| Metric | A measurement of how good the model is using the validation set, chosen for human consumption |
| Validation set | A set of data held out from training, used only for measuring how good the model is |
| Training set | The data used for fitting the model; does not include any data from the validation set |
| Overfitting | Training a model in such a way that it remembers specific features of the input data, rather than generalizing well to data not seen during training |
| CNN | Convolutional neural network; a type of neural network that works particularly well for computer vision tasks |
Machine learning is a discipline in which we define a program not by writing it entirely ourselves, but by learning from data. Deep learning is a specialty within machine learning that uses neural networks with multiple layers. Our goal is to produce a program, called a model.
- Every model starts with a choice of architecture (e.g CNN), a general template for how that kind of model works internally.
- The process of training (or fitting) the model is the process of finding a set of parameter values (or weights) that specialize that general architecture into a model that works well for our particular kind of data.
- To define how well a model does on a single prediction, we need to define a loss function, which determines how we score a prediction as good or bad.
Training (or fitting) a model involves adjusting its parameters (or weights) so that it performs well on the specific data it's being applied to. This process customizes the model's general architecture to make accurate predictions or classifications for that particular dataset. To evaluate a model's performance on a single prediction, we use a loss function. This function measures how well or poorly the model's prediction matches the actual outcome, assigning a numerical score to indicate the accuracy of the prediction.
- To make the training process go faster, we might start with a pretrained model, a model that has already been trained on someone else’s data. We can then adapt it to our data by training it a bit more on our data, a process called fine-tuning.
- The risk is that if we train our model badly, instead of learning general lessons, it effectively memorizes what it has already seen, and then it will make poor predictions about new images. Such a failure is called overfitting.
- To avoid this, we always divide our data into two parts, the training set and the validation set.
- In order for a person to assess how well the model is doing on the validation set overall, we define a metric. During the training process, when the model has seen every item in the training set, we call that an epoch.
- Creating a model that can recognize the content of every individual pixel in an image is called segmentation
Validation Sets and Test Sets
- If we trained a model with all our data and then evaluated the model using that same data, we would not be able to tell how well our model can perform on data it hasn’t seen. It would become good at making predictions about that data but would perform poorly on new data.
- If it makes an accurate prediction for a data item, that should be because it has learned characteristics of that kind of item, and not because the model has been shaped by actually having seen that particular item.
- In realistic scenarios we rarely build a model just by training its parameters once, Instead, we are likely to explore many versions of a model through various modeling choices regarding network architecture, learning rates, data augmentation strategies.
Hyperparameters in deep learning are settings or configurations that are set before training a model and cannot be learned from the data. Examples include learning rate, batch size, number of epochs, and network architecture parameters like the number of layers and units per layer. They influence how the model is trained and its performance.
- We must hold back the test set data even from ourselves. It cannot be used to improve the model; it can be used only to evaluate the model at the very end of our efforts.
- Training data is fully exposed, the validation data is less exposed, and test data is totally hidden.
- Make sure that you hold out some test data that the vendor never gets to see.
- A key property of the validation and test sets is that they must be representative of the new data you will see in the future.
QA
Neural Networks: A Brief History
Q1: Who developed the first mathematical model of an artificial neuron? A1: Warren McCulloch, a neurophysiologist, and Walter Pitts, a logician, developed the first mathematical model of an artificial neuron in 1943. Q2: What was the Mark I Perceptron, and who invented it? A2: The Mark I Perceptron was one of the first artificial neural networks designed for pattern recognition tasks. It was developed by Frank Rosenblatt in 1958. Q3: What significant contribution to neural networks was made in 1986? A3: In 1986, the Parallel Distributed Processing (PDP) framework by David Rumelhart, James McClelland, and the PDP Research Group was introduced, which emphasized distributed representation and parallel processing, mirroring how the brain processes information.
Deep Learning
Q4: What are common traits among individuals who excel at deep learning? A4: Traits include playfulness, curiosity, and a motivation to improve models for better performance. Q5: What type of data can be used in deep learning? A5: Deep learning can work on diverse datasets, including images, emails, financial indicators, sounds, and more.
First Model (Predict Cats)
**Q6: What is the purpose of the valid_pct parameter in the cat prediction model?
A6: The valid_pct parameter specifies the percentage of data to be used for validation, which was set to 20% in the example.
**Q7: What does the is_cat function do in the model?
A7: The is_cat function labels an image as a cat if its filename starts with an uppercase letter.
Q8: Why is image resizing to 224x224 pixels common in deep learning?
A8: This size is historically standard due to its compatibility with pre-trained models. Larger sizes may improve accuracy but increase computational cost.
Machine Learning
Q9: What is Arthur Samuel’s definition of machine learning? A9: Samuel defined machine learning as a way for computers to learn tasks by analyzing examples of the problem, rather than following explicitly programmed steps. Q10: How do weights function in machine learning models? A10: Weights are numerical values that adjust during training to minimize prediction errors, effectively learning patterns in the input data.
Artificial Neural Network (ANN)
Q11: Why are neural networks considered flexible? A11: Neural networks can solve a wide range of problems by adjusting their weights, making them adaptable to various tasks. Q12: What is stochastic gradient descent (SGD), and how is it different from traditional gradient descent? A12: SGD updates model parameters incrementally after evaluating each training example or batch, unlike traditional gradient descent, which calculates gradients using the entire dataset.
Limitations in Machine Learning
Q15: What is overfitting, and why is it problematic? A15: Overfitting occurs when a model learns specific details and noise in the training data, performing well on training data but poorly on unseen data. It reduces the model's generalizability. Q16: Why is labeled data essential for machine learning? A16: Labeled data is required to train models since it provides the correct answers (e.g., “dog” or “cat”), enabling the model to learn patterns and make accurate predictions.
Validation Sets and Test Sets
Q17: Why is a test set kept hidden during model training? A17: A test set is kept hidden to ensure that model evaluation is unbiased and reflects how the model will perform on new, unseen data. Q18: What are hyperparameters, and how do they differ from parameters? A18: Hyperparameters are settings defined before training (e.g., learning rate, batch size), whereas parameters (weights and biases) are learned by the model during training.